Daten einlesen und verarbeiten
Contents
3.5. Daten einlesen und verarbeiten#
In diesem Teil geht es darum Daten aus Dateien einzulesen, diese zu verarbeiten und dann zu visualisieren
verwendete Bibliotheken:
pandas(Datenverarbeitung)numpy(Datenverarbeitung)matplotlib(Datenvisualisierung)
3.5.1. Global: Durchschnittstemperatur (Land und Ozean zusammen)#
Wir wollen nun die globalen Temperaturen visualisieren und greifen dazu auf die Daten der NASA zurück.
Es werden somit Daten von Dateien (online oder offline) eingelesen mit der Python Bilbiothek pandas
3.5.1.1. Daten importieren#
import pandas as pd
link = "https://data.giss.nasa.gov/gistemp/graphs_v4/graph_data/Global_Mean_Estimates_based_on_Land_and_Ocean_Data/graph.csv"
Temp_NASA = pd.read_csv(link, header=1) # einlesen
Temp_NASA # Ausgabe
Die Spalten können nun über den Namen des DataFrames und die jeweilige Spalte in eckigen Klammern mit Hochkommas verwendet werden, z.B.:
Temp_NASA["Year"]
3.5.1.2. Daten plotten#
3.5.1.2.1. q1) Aufgabe#
Plotten Sie die Spalte
No_Smoothing(Werte) undLowess(5)(Glättung) über die (Jahre) mit der SpalteYear.Passen Sie ihren Plot mit Hilfe der Einstellungen für Linien und Marker soweit an, dass die Kurve der Glättung (
Lowess(5)) von den Jahresdaten gut zu unterscheiden ist.
Hinweis: Einstellungen für Linien und Punkte
import matplotlib.pyplot as plt
# Lösung hier
# Kontrolle der Lösung
3.5.1.3. Datenverarbeitung#
Die Bibliothek pandas ist sehr umfangreich und wird viel zur Datenverarbeitung genutzt. Im folgenden dazu einige Beispiele
alle Spalten analysieren (Anzahl/Mittelwert/Min/Max/Percentile)
Temp_NASA.describe()
Maximum bestimmen (Beispiel: stärkster Tempetaturunterschied)
Temp_NASA["No_Smoothing"].max()
index zum Maximum bestimmen (Beispiel: Jahr des stärksten Tempetaturunterschieds)
Es wird ein
index(entspricht meistens Zeilennummer) ausgegeben
index_max = Temp_NASA["No_Smoothing"].idxmax()
print(index_max)
mit dem .loc Befehl wird die Tabelle mit nun gefunden index ausgegeben werden
Temp_NASA.loc[index_max]
Mit .sort_values("Spaltenname") können wir auch die Tabelle nach dem definierten Spaltennamen sortieren (standardmäßig in ansteigender Reihenfolge)
Temp_NASA.sort_values("No_Smoothing")
mit ascending=False wird absteigend sortiert
Temp_NASA.sort_values("No_Smoothing",ascending=False)
mit .head(Anzahl) können wir angeben wieviele Zeilen (vom Kopf beginnend) angezeigt werden. Mit .tail(Anzahl) erfolgt die ausgabe der letzten Werte mit der jeweiligen Anzahl
WICHTIG: Der Dataframe Temp_NASA wird dadurch nicht verändert, es handelt sich nur um eine Anzeige!
3.5.1.4. Glättung#
Die von der NASA verwendete Glättung ist die LOcally WEighted Scatter-plot Smoother (LOWESS). Dabei wird in einem lokal zu definierenden Bereich eine lineare Regression durchgeführt. Eine genauere Erklärung zur Methode findet ihr hier.
Wir benutzen nun diese Methode und erstellen eine neue Spalte Lowess(own)
from statsmodels.nonparametric.smoothers_lowess import lowess
Temp_NASA["Lowess(own)"] = lowess(Temp_NASA["No_Smoothing"],Temp_NASA["Year"], frac=1/14)[:,1]
Ausgabe der Tabelle (Temp_NASA) mit der neuen Spalte Lowess(own)
Temp_NASA
Wir plotten nun unsere eigene Glättung gegenüber der bereits vorhandenen
import matplotlib.pyplot as plt
plt.style.use('default')
plt.figure(figsize=(10,4))
plt.rcParams['font.size'] = 14;
plt.ylabel("Jahresmitteltemperaturabweichung [K]")
plt.plot(Temp_NASA["Year"],Temp_NASA["No_Smoothing"], ls="-", lw=1, marker="s", ms=3, color="tab:gray", alpha=0.5, label="Werte");
plt.plot(Temp_NASA["Year"],Temp_NASA["Lowess(5)"], lw=4, color="tab:blue", label="Glättung (NASA)");
plt.plot(Temp_NASA["Year"],Temp_NASA["Lowess(own)"],ls="--",lw=2, color="orange", label="eigene Glättung (LOWESS f=1/14)");
plt.legend();
plt.grid();
Die Glättung scheint gut mit der von NASA durchgeführten übereinzustimmen
3.5.2. Global: Durchschnittstemperatur (Land + Ozean getrennt)#
Nun schauen wir uns die Daten an in denen die Temperaturen für die Landmasse und den Ozean getrennt ausgegeben werden
3.5.2.1. Daten importieren#
link = "https://data.giss.nasa.gov/gistemp/graphs_v4/graph_data/Temperature_Anomalies_over_Land_and_over_Ocean/graph.csv"
Temp_NASA2 = pd.read_csv(link, header=1) # einlesen
Temp_NASA2 # Ausgabe
3.5.2.2. Daten plotten#
3.5.2.2.1. q2) Aufgabe#
Stellen Sie die Kurven für die Erwärmung an Landoberfläche und an der Ozeanoberfläche mit jeweils den Jahreswerten und den geglätteten Werten grafisch dar
Tipp: Verwenden Sie für Land und Ozean jeweils die gleiche Farbe und reduzieren Sie die Sichtbarkeit der nicht geglätteten Werte zur besseren Übersicht
Beschriften Sie das Diagramm entsprechend
# Lösung hier
3.5.3. Deutschland: Durchschnittstemperatur (Land)#
Beim Umweltbundesamt gibt es aktuelle Zahlen zur Erwärmung der Luftemperatur in Deutschland. Die Werte befinden sich in dieser Exceltabelle, welche mit dem Befehl pd.read_excel() eingelesen werden kann, wobei hierbei der Name des ExcelSheets und die verwendenten Spaltennummern angegeben werden können.
3.5.3.1. Daten importieren#
# Einlesen
link = "https://www.umweltbundesamt.de/sites/default/files/medien/384/bilder/dateien/3-bis-8_abb-tab_tmt_2021-05-12.xlsx"
Temp_GER = pd.read_excel(link,sheet_name="3_DWD",usecols=[1,19]) # einlesen
Temp_GER.columns=["Jahr","Jahresmitteltemperatur [°C]"]
Temp_GER
3.5.3.2. Daten aufbereiten#
In den Daten befindet sich einige NaN Werte (Not a Number), die wir mit der Funktion .dropna(inplace=True) entfernen
# Daten aufbereiten
Temp_GER.dropna(inplace=True) # Zeilen mit "NaN" Werte rausschmeissen und dataframe speichern
Als nächstes definieren wir die Spalte “Jahr” als integer
Temp_GER["Jahr"] = Temp_GER["Jahr"].astype(int) # Spalte "Jahr" als integer definieren
Temp_GER.head()
Nun berechnen wir die Temperaturabweichung. Dafür verwenden wir die Abweichung von Mittelwert der Temperatur zwischen 1881 und 1900 welche wir zunächst bestimmen. Dafür verwenden wir die Funktion .loc() und können damit angeben welche Zeilen wir haben haben wollen (die zwischen 1910 und 1985) und können dann von der Spalte Jahresmitteltemperatur [°C] den Mittelwert bestimmen mit .mean()
mean_GER1881_1910 = Temp_GER.loc[Temp_GER["Jahr"] <= 1910,"Jahresmitteltemperatur [°C]"].mean()
mean_GER1881_1910
Wir ziehen von der Spalte Jahresmitteltemperatur [°C] den nun berechneten Wert mean_GER1881_1910 und nennen diese neue Spalte Jahresmitteltemperaturabweichung [K]
Temp_GER["Jahresmitteltemperaturabweichung [K]"] = Temp_GER["Jahresmitteltemperatur [°C]"] - mean_GER1881_1910
Temp_GER
als nächstes verwenden wir nun wieder die lowess Glättung die wir bereits bei den NASA Daten verwenden haben. Die neue Spalte nennen wir Lowess(own)
# Glättung
from statsmodels.nonparametric.smoothers_lowess import lowess
Temp_GER["Lowess(own)"] = lowess(Temp_GER["Jahresmitteltemperaturabweichung [K]"],Temp_GER["Jahr"], frac=1/14)[:,1]
Temp_GER
3.5.3.3. Daten plotten#
3.5.3.3.1. q3) Aufgabe#
Stellen Sie folgende Daten zusammen dar:
global: Land (geglättet) <- NASA
Deutschland: Land (Werte) <- DWD
Deutschland: Land (geglättet) <- DWD
Verwenden Sie eine entsprechende Formatierung und beschriften Sie das Diagramm
# Lösung hier
3.5.3.4. Vergleich mit Abbildung aus Leoplodina Factsheet#
Vergleichen wir diese Darstellung nun mal mit einer aus dem Factsheet der Leopoldina:
Nationale Akademie der Wissenschaften Leopoldina (2021): Klimawandel: Ursachen, Folgen und Handlungsmöglichkeiten. Halle (Saale).
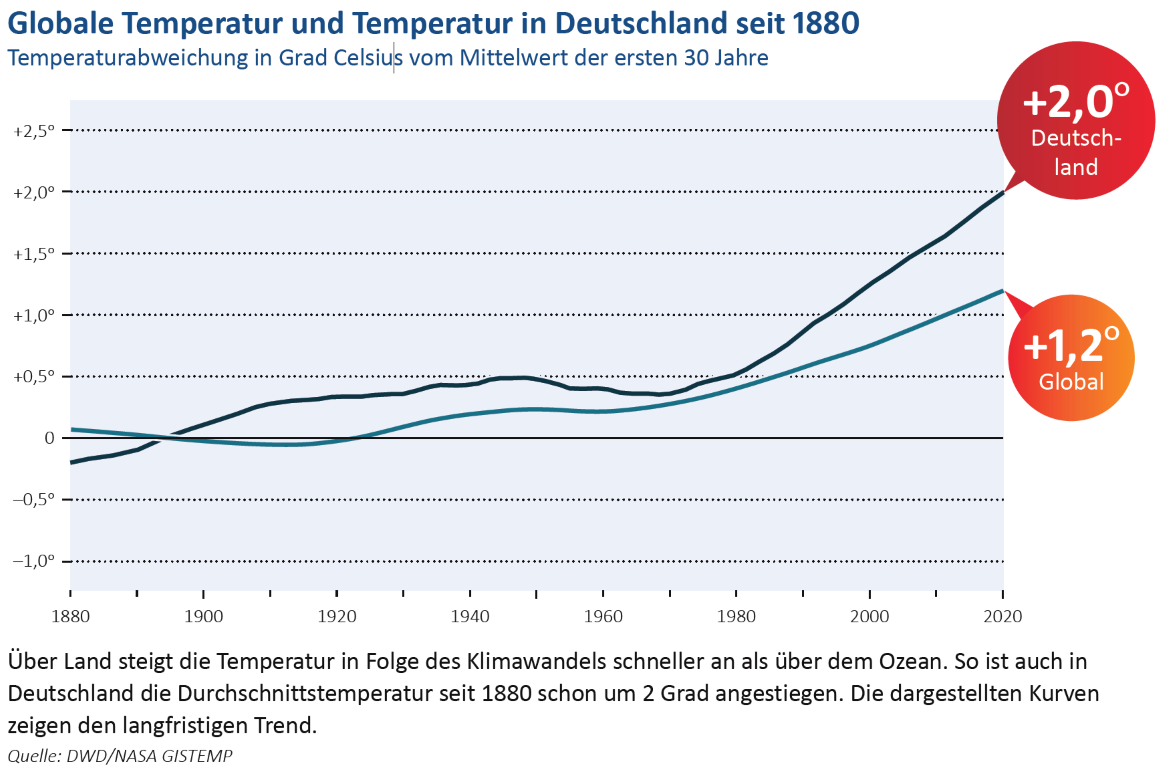
Hierbei wurde scheinbar eine sehr starke Glättung der Messdaten verwendet, wir erhöhen also den Wert frac für die LOWESS Methode und prüfen ob wir in ähnliche Bereiche kommen
# Glättung
from statsmodels.nonparametric.smoothers_lowess import lowess
Temp_GER["Lowess(own2)"] = lowess(Temp_GER["Jahresmitteltemperaturabweichung [K]"],Temp_GER["Jahr"], frac=1/3)[:,1]
Temp_GER_Lowess_own2_mean_untill_1910 = Temp_GER.loc[Temp_GER["Jahr"] <= 1910,"Lowess(own2)"].mean()
Temp_GER["Lowess(own2)"] = Temp_GER["Lowess(own2)"] - Temp_GER_Lowess_own2_mean_untill_1910
Temp_NASA["Lowess(own3)"] = lowess(Temp_NASA["No_Smoothing"],Temp_NASA["Year"], frac=1/3)[:,1]
Temp_NASA_Lowess_own3_mean_untill_1910 = Temp_NASA.loc[Temp_NASA["Year"] <= 1910,"Lowess(own3)"].mean()
Temp_NASA["Lowess(own3)"] = Temp_NASA["Lowess(own3)"] - Temp_NASA_Lowess_own3_mean_untill_1910
plt.style.use('default')
plt.figure(figsize=(10,4))
plt.rcParams['font.size'] = 14;
plt.ylabel("Jahresmitteltemperaturabweichung [K]")
plt.plot(Temp_NASA["Year"],Temp_NASA["Lowess(own3)"], lw=3, color="tab:red", label="global: Land+Ozean (eigene Glättung frac=1/3) [NASA]");
plt.plot(Temp_GER["Jahr"],Temp_GER["Lowess(own2)"], ls="-", lw=2, color="gray", label="Deutschland Land (Glättung frac=1/3) [DWD]");
plt.legend(fontsize=12);
plt.grid();
Ausgabe der Temperaturdifferenz im Jahr 2020
Temp_NASA.loc[Temp_NASA["Year"] == 2020]
Temp_GER.loc[Temp_GER["Jahr"] == 2020]
Eine weitere Variante den Temperaturanstieg zu berechnen wäre eine einfache lineare Regression. Dafür verwenden wir die numpy Funtion np.polyfit.
import numpy as np
x=Temp_GER["Jahr"]
y=Temp_GER["Jahresmitteltemperatur [°C]"]
model = np.polyfit(x, y, 1) # 1. Wert = Anstieg , 2. Wert = Schnittpunkt mit y-Achse
model
Die Werte werden als Array gespeichert. Mit eckigen Klammern können wir auf das erste Element model[0] (Python Zählweise beginnt immer bei 0) und das zweite Element mit model[1]. Mit den Werten können wir nun eine Geradengleichung erstellen
y_model = model[0]*x+model[1]
Nun stellen wir dies grafisch dar:
plt.plot(Temp_GER["Jahr"],Temp_GER["Jahresmitteltemperatur [°C]"], ls="-", lw=1,marker="s", ms=3, color="gray",alpha=0.5, label="Deutschland Land (Werte) [DWD]");
plt.plot(x,y_model, ls="-", lw=3, color="tab:blue",alpha=0.5, label=f"lineare Regression (y={model[0]:.3f}*x+{model[1]:.3f})");
plt.ylabel("Jahresmitteltemperaturabweichung [K]")
plt.legend(fontsize=12);
plt.grid();
print(f"Temperaturanstieg pro Jahr (von 1981 bis 2020): {model[0]:.3f}°C/Jahr")
print(f"Temperaturanstieg seit Beginn der Messung: {(y_model.iloc[-1]-y_model.iloc[0]):.3f}°C")
Vorsicht: Die lineare Regression bezieht hier den ganzen Zeitraum mit ein, betrachten wir für den Temperaturgradienten nur die Daten von 1980 bis 2020:
Wir machen dies also erneut, aber nur mit den Daten ab 1980:
x=Temp_GER.loc[Temp_GER["Jahr"] >= 1980,"Jahr"]
y=Temp_GER.loc[Temp_GER["Jahr"] >= 1980,"Jahresmitteltemperatur [°C]"]
model = np.polyfit(x, y, 1) # 1. Wert = Anstieg , 2. Wert = Schnittpunkt mit y-Achse
y_model = model[0]*x+model[1]
print(f"Temperaturanstieg pro Jahr (von 1980 bis 2020): {model[0]:.3f}°C/Jahr")
Visualisierung:
plt.plot(Temp_GER["Jahr"],Temp_GER["Jahresmitteltemperatur [°C]"], ls="-", lw=1,marker="s", ms=3, color="gray",alpha=0.5, label="Deutschland Land (Werte) [DWD]");
plt.plot(x,y_model, ls="-", lw=3, color="tab:blue",alpha=0.5, label=f"lineare Regression (y={model[0]:.3f}*x+{model[1]:.3f})");
plt.ylabel("Jahresmitteltemperaturabweichung [K]")
plt.legend(fontsize=12);
plt.grid();
3.5.4. Treibhausgasemissionen#
Zunächst stellen wir die Treibhausgas-Konzentrationen dar
Quelle : Umweltbundesamt
3.5.4.1. Daten imortieren#
link = "https://www.umweltbundesamt.de/sites/default/files/medien/384/bilder/dateien/6_abb_treibhausgas-gesamt-konz_2020-06-03.xlsx"
THG_Emission_UBA = pd.read_excel(link,sheet_name="Daten",usecols=[1,2],header=8) # einlesen
THG_Emission_UBA.head()
3.5.4.2. Daten Plotten#
3.5.4.2.1. q4) Aufgabe#
Stellen Sie die Treibhausgasemissionen über die Jahre dar
Verwenden Sie eine entsprechende Formatierung und beschriften Sie das Diagramm
# Lösung hier
3.5.5. Vergleich zweier CO2 Messtationen#
Auf der Seite vom Umweltbundesamt findet man auch CO2 Messwerte verschiedener Messtationen:
Quelle : Umweltbundesamt
Quelle Welttrend WMO
Quelle Mauna Loa
Quelle Schauinsland und Zugspitze
link="https://www.umweltbundesamt.de/sites/default/files/medien/384/bilder/dateien/2-4_abb_langzeitreihen-konz_2021-05-26.xlsx"
CO2_Emission_UBA = pd.read_excel(link,sheet_name="Kohlendioxid-Daten",usecols=[0,1,2,3,4]) # einlesen
CO2_Emission_UBA.columns = ["Jahr","Mauna Loa, Hawaii","Schauinsland","Zugspitze","Welttrend WMO"]
CO2_Emission_UBA.head()
3.5.5.1. q5) Aufgabe#
Stellen Sie die CO2 Werte aller Messtationen und dem WMO Trend zusammen dar
# Lösung hier
3.5.6. Übersicht Treibhausgase#
Excel-Tabelle: https://www.umweltbundesamt.de/sites/default/files/medien/384/bilder/dateien/5_abb_beitrag-treibhauseffekt-co2-thg_2021-05-26.xlsx
Quelle Daten: NOAA Earth System Research Laboratory, The NOAA annual greenhouse gas index (AGGI), https://www.esrl.noaa.gov/gmd/aggi/aggi.html
Wir stellen die Daten nun als Balkendiagramm mit plt.bar() dar
# Daten
Beitrag = np.array([2076,516,202,161,57,129])
Beitrag_Prozent = Beitrag/Beitrag.sum()*100
Bezeichnung = np.array(["Kohlendioxid (CO₂)","Methan (CH₄)","Lachgas (N₂O)","Dichlordifluormethan (CFC-12)","Trichlorfluormethan (CFC-11)","15 weitere Treibhausgase"])
# Plot
plt.bar(Bezeichnung,Beitrag_Prozent);
plt.ylabel('Anteil [%]');
plt.title('Beitrag zum Treibhauseffekt durch verschiedene Treibhausgase', fontsize=12);
Da die Beschriftung so nicht lesbar ist können wir Sie über die Funktion plt.xticks(rotation=30, ha='right') um 30° drehen. Weiterhin fügen wir ein Grid für die y-Achse ein und setzen dies hinter den plot.
# Plot
plt.bar(Bezeichnung,Beitrag_Prozent);
plt.ylabel('Anteil [%]');
plt.title('Beitrag zum Treibhauseffekt durch verschiedene Treibhausgase', fontsize=12);
# Beschriftung x Ticks um 30° drehen
plt.xticks(rotation=30, ha='right', fontsize=12);
# Grid für y-Achse einstellen
plt.grid(axis='y');
# Grid hinter Balkendiagramm
plt.gca().set_axisbelow(True);
Mit plt.hbar() wird das Balkendiagramm horizontal ausgerichtet
# Plot
plt.barh(Bezeichnung,Beitrag_Prozent)
plt.ylabel('Anteil [%]')
plt.title('Beitrag zum Treibhauseffekt durch verschiedene Treibhausgase', fontsize=12);
plt.grid(axis='x');
plt.gca().set_axisbelow(True);
Wenn wir die Einträge sortieren möchten, müssen wir die Listen in ein pandas dataframe einfügen
THG_Anteil = pd.DataFrame(data=([Bezeichnung,Beitrag,Beitrag_Prozent])).T
THG_Anteil.columns=["Name","Anteil","Anteil [%]"]
THG_Anteil
Wenn wir den Dataframe jetzt so einfach ausführen ist die Sortiertung wieder weg:
THG_Anteil
Deshalb müssen wir den Dataframe neu speichern wenn wir die Sortierung dauerhaft in der Tabelle haben wollen
THG_Anteil = THG_Anteil.sort_values("Anteil [%]",ascending=False)
THG_Anteil
Beim erneuten Ausführen des plots hat sich dadurch jetzt auch die Reihenfolge geändert:
# Plot
plt.barh(THG_Anteil["Name"],THG_Anteil["Anteil [%]"])
plt.ylabel('Anteil [%]')
plt.title('Beitrag zum Treibhauseffekt durch verschiedene Treibhausgase', fontsize=12);
plt.grid(axis='x');
plt.gca().set_axisbelow(True);